In .NET, it is commonplace to use byte arrays when working with binary data; for example, passing the contents of a file between methods, encoding/decoding text, reading data from sockets, etc. These arrays can get quite large (up to megabytes in size), which can eventually lead to OutOfMemoryException being thrown if the runtime is unable to allocate a large enough block of memory to hold the array. Since arrays are always allocated as a single, contiguous block, this exception can be thrown even when there is more than ample memory available. This is due to fragmentation, where used blocks of memory occupy a sparse range of addresses, and available memory exists only as small gaps between these blocks.

One way to avoid this problem is to only operate on a small number of bytes at a time, using a buffer. This approach is often used in conjunction with streams. For example, we can avoid loading an entire file into memory by using a FileStream and reading its contents into a small array, say 4KB at a time. This can be a very efficient way to use memory, provided that the data comes from an external source and can be exposed via a Stream object.
When this is not the case, the MemoryStream class often comes into play. This type allows us to read and write data, still in small sections at a time if desired, without using I/O. You might use a memory stream to perform on-the-fly conversion of data, for example, or to make a seekable copy of a stream that doesn’t normally support this. However, there is a significant limitation in that the backing store for a memory stream is just a large byte array! As such, it suffers from the same issues in terms of contiguous allocation and vulnerability to memory fragmentation.
So, whether it’s large byte arrays of memory streams, either way you can run into OutOfMemoryException if you use these mechanisms frequently or in large volumes.
Arrays vs Linked Lists
When we look at various collection types and their implementations, there is a stark difference between arrays and linked lists. While arrays require a contiguous block of memory, linked lists are able to span multiple non-contiguous addresses. So, at first glance, a linked list of bytes might seem to be a reasonable solution to our problem.
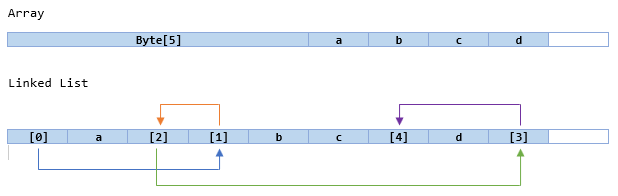
The problem with using a straight linked list of bytes is that each byte requires 4 additional bytes (or 8 on 64-bit machines) to store the address of the next element, making it extremely inefficient in terms of storage. Also, arrays are of fixed length while linked lists tend to grow and shrink as needed; since each new element requires memory to be allocated, writing to a linked list is much slower.
Furthermore, linked lists cannot benefit from the Buffer.BlockCopy() method, which offers vastly improved performance when copying between byte arrays.
A Hybrid Solution
An ideal solution would give us the best of both worlds; i.e. the non-contiguous nature of linked lists with the performance benefits of arrays. In other words, a linked list of smaller arrays. Since our goal is to ultimately replace both large byte arrays and the MemoryStream class, the solution needs to be both writable and of variable length.

In order to utilise available memory in the most efficient way, each of these smaller arrays should be equal to (or a multiple of) the size of each block of memory allocated by the operating system. In the case of Windows (at least at the time of writing), virtual memory is allocated in blocks of 4KB. This is known as the page size. By aligning the arrays to the page size, we avoid wasting any of the memory we allocate (and thus depriving other parts of our code of it).
If we are going to want to write to this structure, it is better to allocate the entire 4KB once to each array than to have to re-declare and copy over the existing data each time its length changes. The effect of this decision is that we require an additional field on each node that stores the number of bytes actually used. This would also mean that even a 1-element collection would still occupy 4KB of memory. We can avoid this by making an exception for the first array.
Indexing
To access the byte at a particular offset in the collection, we need to traverse the linked list until we reach the node containing the offset, then get/set that element in that node’s array.
Reading
Reading an arbitrary number of bytes from this collection involves two steps:
- Traverse the linked list until we reach the node containing the offset from which we want to start reading.
- Copy bytes from the array to the destination. If there are still more bytes to copy after the number of used bytes is reached, traverse to the next node and repeat this step.
Writing
Writing an arbitrary number of bytes to this collection consists of these steps:
- Traverse the linked list until we reach the node containing the offset at which we want to start writing.
- If there are more nodes after the current node, copy up to the number of used bytes only; otherwise, copy up to the full length of the array and update the number of used bytes. (This avoids inserting data when our intention is to replace or append it)
- If there are more bytes to write, traverse to the next node. If it does not exist, create it. Repeat from step 2.
Inserting
Although this is not normally possible with streams or byte arrays, the ability to insert an arbitrary number of bytes at some point in the collection would be quite desirable. For example, say you received a series of packets over a UDP connection and wanted to reconstruct the message in the correct order, you could simply insert the bytes from each packet at the desired offset. Without this functionality, several arrays would be required and you would likely have to duplicate the data in memory.
Inserting involves these steps:
- Traverse the linked list until we reach the node containing the offset at which we want to insert the data.
- Truncate the array (that is, update the number of used bytes) at this offset and copy the remaining bytes into a temporary array. (If the array is completely unused, skip this step)
- Copy bytes until the array is full. If more arrays are needed, insert them after the current node and repeat.
- Copy the remaining bytes from step 2 into the current array (inserting another node if required).
Following an insert operation, there may be ‘gaps’ in the collection where the number of used bytes is less than the length of each array. Removing these gaps would be an expensive operation.
Deleting
As a complimentary operation to insertion, it should be possible to remove an arbitrary number of bytes from the collection, starting at any offset. The process involves:
- Traverse the linked list until we reach the node containing the starting offset from which we want to delete data. Capture this node.
- Keep traversing the linked list until we reach the node containing the end offset (start + count). Capture this node.
- Copy the trailing bytes after the end offset (in the end node) into a temporary array. (If there are no trailing bytes in the array, skip this step)
- Truncate the array (that is, update the number of used bytes) in the start node after the starting offset.
- Insert the trailing bytes from step 3 after the starting offset.
- Remove all intermediate nodes from the linked list (by updating the ‘next’ and ‘previous’ markers), including the end node.
As with insertion, deletion may create ‘gaps’ in the collection.
Serialisation
It is sometimes necessary to serialise a byte sequence; for example, in order to embed the data within an XML document, or to marshal it between application domains. Since this functionality is supported for byte arrays and memory streams, our collection should also implement it.
Accepting the default binary serialisation would result in a sub-optimal result, so we will provide custom logic by implementing ISerializable. The same goes for the XML serialiser (in fact it likely wouldn’t work at all), so we will also implement IXmlSerializable. For the former, the serialized form is a sequence of byte arrays mirroring those in our collection, followed by the total number of arrays. For the latter, only the arrays need to be written (using Base64 encoding).
Stream Implementation
Up to this point, we have implemented a collection of bytes that can be used in much the same way as a conventional byte array; indexing, reading, writing and so on. Now, we want to implement a stream class that uses our collection as a backing store, and can be used instead of MemoryStream. Together, these two types should allow us to avoid having to allocate contiguous blocks of memory, thus avoiding OutOfMemoryException (except when the process genuinely runs out of memory, of course, which we can do nothing about).
Streams provide 3 basic operations; reading, writing and seeking. To read data into a buffer, we can simply read from the underlying collection using the functionality we already implemented, starting from the stream’s position marker. The same applies to writing. After each operation, we need to increment the position marker by the number of bytes actually read/written. Finally, seeking is achieved by directly manipulating the position marker.
An advanced use case for streams is being able to change the length of the stream. This can be achieved by either truncating the collection (see Deletion above) or by adding the required number of bytes to the end of the collection.
Results
To see whether the benefits offered by our new collection are actually being delivered, I ran a simple test that could be applied equally to it or to conventional byte arrays: A large number of bytes (in this case, 10MB worth) are allocated and the result is held in a list (to prevent the garbage collector from reclaiming the memory). This process repeats indefinitely until an OutOfMemoryException is thrown, at which point the number of iterations is measured. I observed that the non-contiguous method consistently survived for 50% more iterations than using byte arrays.
It’s not all good news, however. As you would expect, there is a performance penalty for a more efficient use of memory, and the non-contiguous method takes considerably longer to complete (several orders of magnitude, in fact). This is because the non-contiguous allocation of memory is an O(n) operation compared to O(1) for arrays. This means that it takes 2560 times longer to allocate 10MB non-contiguously than it does as an array. You can improve this by choosing a larger block size (e.g. a 32KB block size resulted in a significantly faster run without significantly fewer iterations) but if the size is too great, it defeats the purpose of allocating the memory non-contiguously in the first place. This also relies on the caller knowing the total length of the data, which cannot be guaranteed.
Ultimately, this collection and stream type are designed to solve a very specific problem, and I would recommend using this approach if memory fragmentation is an issue that affects your code too. I would stop short of recommending it for general use, or as a replacement for byte arrays and MemoryStream entirely.
Download
The source code for this project is available on GitHub: https://github.com/BradSmith1985/NonContig