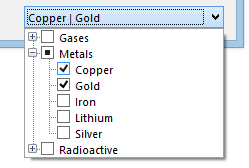
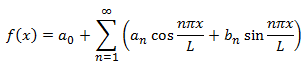This is just a quick update to announce another update to my Drop-Down Controls project. By request (and because I always enjoy a challenge), i’ve added custom DataGridView column types for the ComboTreeBox and GroupedComboBox controls. This means that you can now use these controls from within a DataGridView, taking advantage of the automatic support for reading/writing to a data source that comes with it.
Creating custom column types
The general process for implementing a custom DataGridView column type is as follows:
- Create a class that derives from
DataGridViewColumnthat will represent the column and properties that apply to all of its cells. Be sure to override theClonemethod. - Create a class that derives from
DataGridViewCellthat will represent the individual cells, including any properties that override those inherited from the column. As above, override theClonemethod. You will also need to override thePaintmethod to draw the cell’s “normal” appearance (i.e. when the cell is not in edit mode). In the constructor for the column class, set theCellTemplateproperty to a new instance of the cell class. - Create a class that derives from
Controland implements theIDataGridViewEditingControlinterface, which will be responsible for editing a cell’s value. (Alternatively, the cell can implement theIDataGridViewEditingCellinterface if it provides in-place editing… but this is only useful when the editing UI is very simple.) Override theEditTypeproperty of the cell class to return the type of the editing control. Also override theInitializeEditingControlmethod to set the initial value of the control and set up any other behaviours.
In all of the above, you can use a more derived base class than those mentioned (e.g. DataGridViewTextBoxColumn, DataGridViewComboBoxCell, DateTimePicker, etc). In this case, since I already have controls to use as editors, I will extend those. However, for the column and cell classes, it’s easier to start from scratch.
GroupedComboBoxColumn
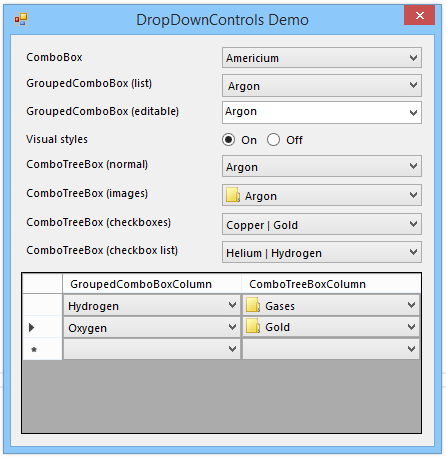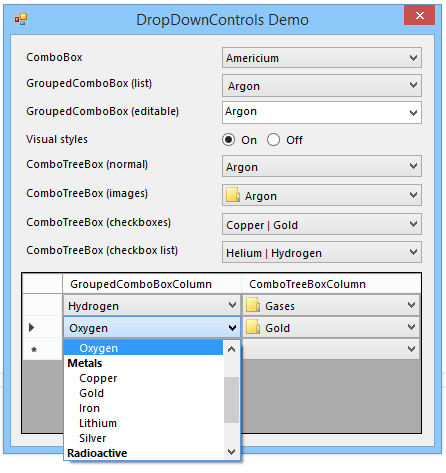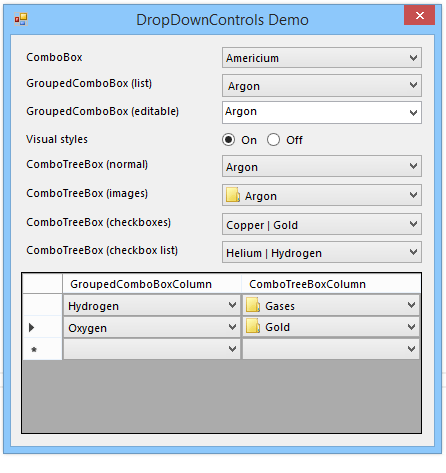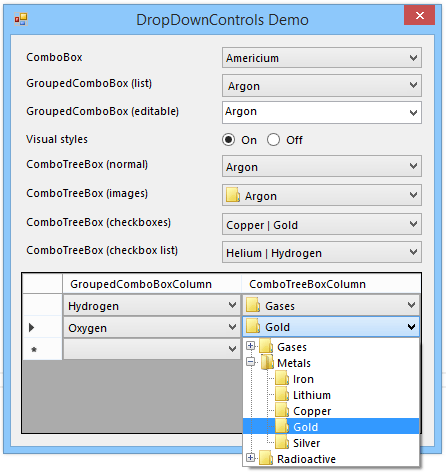
The first custom column type I added is based on my GroupedComboBox control. Itself extending the built-in ComboBox control, it behaves very much like the DataGridViewComboBoxColumn. However, because the control does some custom painting and manipulation of the data source, it was easier to implement separately from the built-in column type.
Unlike the built-in column, there is no Items property on this column type. Since the grouping functionality relies on being bound to a data source, it makes sense to do this exclusively via the DataSource property. As with the GroupedComboBox itself, you can set the DisplayMember, ValueMember and GroupMember properties to control how the list items behave. All of these properties are optional (although you will not get the grouping behaviour unless you set the latter one).
You can override all of these properties for individual cells; setting the cell’s properties to null (the default) will cause the values to be inherited from the owning column.
ComboTreeBoxColumn
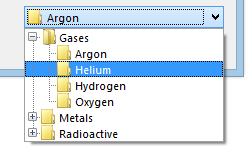
Secondly, the other column type is based on my ComboTreeBox control. There are various challenges associated with populating hierarchical views from flat lists/tables:
The nodes displayed in the drop-down for this column type must be set manually. As with the previous column type, however, you can override the Nodes property for cells on an individual basis (controlled by the UseColumnNodes property).
In terms of actually selecting nodes, the underlying value type for cells in the ComboTreeBoxColumn is simply String. You select a specific node by its path, the format of which is determined by both the PathSeparator and UseNodeNamesForPath properties. This is also used for the formatted value of the cells. The cell itself can display either the path or the node text, depending on the value of ShowPath. All of this means that the underlying cell values (and therefore the values in the data source for the grid) must be path strings.
e.g. The path string Fruit\Citrus\Orange selects the node with the text “Orange” whose immediate parent node is “Citrus” and whose grandparent node is “Fruit”.
Path strings can be translated to/from ComboTreeNode via the GetFullPath and GetNodeAt methods on the ComboTreeBox control.
Download
The latest version of the drop-down controls can be downloaded from the project page.